Blog
What Is a Protein Binding Site? A Beginner’s Guide
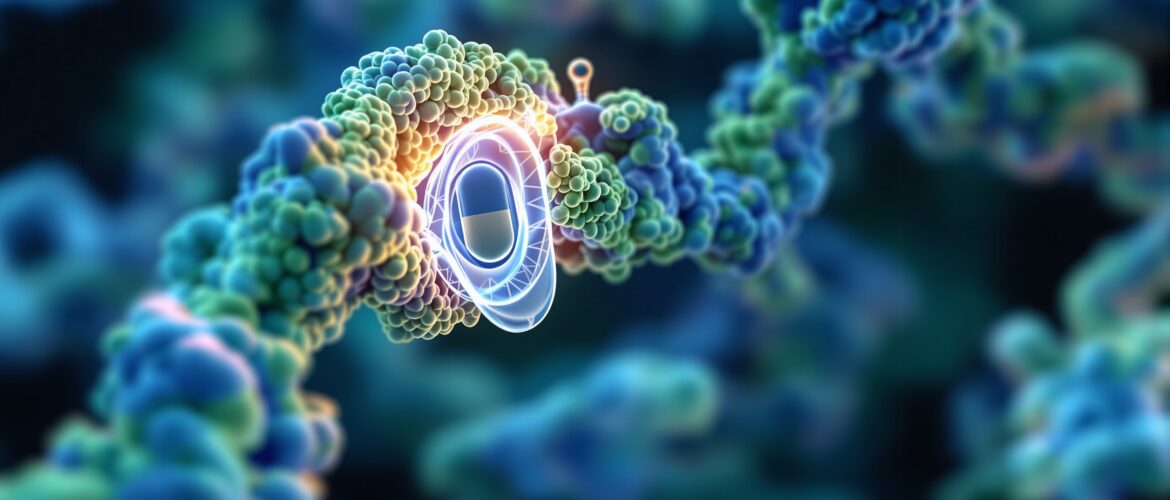
When researchers design new drugs or study how proteins function, they focus intensely on specific regions called protein binding sites. These molecular pockets and grooves are where the real action happens – where drugs attach, where natural molecules interact, and where cellular processes get controlled.
Understanding protein binding sites is fundamental to computational biology, drug discovery, and molecular modeling. Whether you’re a student starting your journey in bioinformatics or an early-career researcher exploring molecular interactions, this guide will help you grasp these critical concepts and apply them in your computational projects.
What Is a Protein Binding Site?
A protein binding site is a specific region on a protein’s surface where other molecules – called ligands – can attach. Think of it like a lock and key mechanism, where the protein binding site is the lock, specifically shaped to accommodate certain molecular “keys.”
These sites are typically:
- Three-dimensional cavities, pockets, or grooves on the protein surface
- Lined with amino acid residues that interact with incoming molecules
- Precisely shaped to fit specific ligands through complementary molecular contacts
- Critical for the protein’s biological function
The shape, size, and chemical properties of protein binding sites determine which molecules can attach and how strongly they bind. This specificity is what makes protein-drug interactions possible and controllable, forming the foundation of modern drug design.
Types of Protein Binding Sites
Not all protein binding sites are created equal. Understanding the different types helps explain how drugs work and how proteins are regulated in living systems.
Active Sites (Orthosteric Sites)
Active sites are the primary functional regions where a protein performs its main biological activity. In enzymes, this is where chemical reactions occur. In receptors, this is where natural signaling molecules bind.
Key characteristics of active sites:
- Highly specific for natural substrates or ligands
- Often deeply buried within the protein structure
- Show high conservation across related proteins
- Targeted by most traditional drugs
For example, in the enzyme acetylcholinesterase, the active site is where the neurotransmitter acetylcholine gets broken down. Many Alzheimer’s drugs work by blocking this active site.
Allosteric Sites
Allosteric sites are secondary binding locations that can regulate protein activity from a distance. When molecules bind to these sites, they cause shape changes that affect the active site’s function.
Allosteric sites offer several advantages:
- Allow fine-tuning of protein activity rather than complete shutdown
- Often more specific between related proteins
- Can enhance or reduce activity (positive or negative regulation)
- Generally flatter and more accessible than active sites
Modern drug discovery increasingly targets allosteric sites because they offer better selectivity and fewer side effects compared to active site inhibitors.
Cryptic Sites
Cryptic binding sites are hidden pockets that only become visible when proteins change shape. These sites aren’t apparent in static protein structures but emerge through molecular motion and flexibility.
Recent computational advances have made cryptic site discovery a hot research area, as they represent untapped opportunities for targeting “undruggable” proteins. According to recent studies published in Bioinformatics Advances, identifying these cryptic sites opens novel opportunities for structure-based drug design by allowing researchers to target proteins previously considered impossible to drug.
Why Protein Binding Sites Matter in Drug Design
Drug discovery fundamentally depends on understanding and targeting protein binding sites. When pharmaceutical companies develop new medications, they’re essentially designing molecules that will fit into specific protein binding sites and modify protein function.
Structure-Based Drug Design
Modern drug design starts with detailed knowledge of protein binding site structure. Researchers use this information to:
- Design molecules that fit perfectly into the target site
- Optimize binding strength and selectivity
- Predict potential side effects from off-target binding
- Understand resistance mechanisms when drugs stop working
Virtual Drug Screening
Computational methods can test millions of potential drug compounds against protein binding sites virtually, before any laboratory work begins. This approach:
- Dramatically reduces time and cost in early drug discovery
- Allows exploration of vast chemical libraries
- Helps prioritize the most promising compounds for experimental testing
- Enables multi-target drug design for complex diseases
How Computational Tools Identify Binding Sites
Finding and analyzing binding sites requires sophisticated computational approaches. Here’s how researchers use technology to map these crucial protein regions.
Geometry-Based Methods
The most straightforward approach involves scanning protein surfaces for cavities and pockets. Software tools search for:
- Concave regions that could accommodate ligands
- Appropriate size and depth for drug-like molecules
- Geometric features suggesting functional importance
Popular tools like CASTp, fpocket, and P2Rank use sophisticated algorithms to identify these geometric features automatically.
Energy-Based Approaches
These methods calculate interaction energies between proteins and probe molecules. They identify sites where favorable binding energies suggest strong ligand attachment potential.
Sequence-Based Prediction
Machine learning approaches analyze protein sequences to predict binding site locations based on evolutionary conservation and amino acid patterns. These methods are particularly useful when protein structures aren’t available.
Molecular Dynamics Simulations
Advanced computational simulations show how proteins move and flex in solution. These dynamic studies reveal:
- Cryptic sites that appear during protein motion
- Binding site flexibility and adaptability
- How mutations might affect binding site properties
- Allosteric communication pathways between sites
Modern AI and Machine Learning Applications
The field is being revolutionized by artificial intelligence approaches that can:
Protein Language Models
Recent 2025 developments include protein language models that can understand binding sites at the sequence level, similar to how language models process text. These models can predict binding site properties directly from protein sequences, making structural analysis accessible even when experimental structures aren’t available.
Deep Learning Integration
Machine learning algorithms now combine multiple data types – sequence, structure, and dynamics – to make more accurate protein binding site predictions. Some recent approaches published in computational biology journals reduce computational costs by over 1000-fold while maintaining accuracy, making these advanced methods accessible to more research groups.
Multi-Target Optimization
AI methods can now design drugs that target multiple binding sites simultaneously, opening new possibilities for treating complex diseases like cancer and neurological disorders.
Practical Applications in Molecular Modeling
Understanding binding sites directly applies to several key areas in molecular modeling and drug design:
Molecular Docking
Docking algorithms predict how drugs bind to specific sites. Accurate binding site identification is crucial for reliable docking results. The process involves:
- Preparing the binding site structure
- Generating drug conformations
- Scoring binding poses
- Ranking potential drugs
Lead Optimization
Once researchers identify promising drug candidates, they use binding site information to improve:
- Binding affinity (how tightly the drug binds)
- Selectivity (binding to the right target, not others)
- Drug-like properties (absorption, metabolism, toxicity)
Resistance Prediction
Understanding binding sites helps predict how mutations might affect drug effectiveness, particularly important for designing antibiotics and cancer therapeutics that must overcome resistance.
Getting Started with Binding Site Analysis
If you’re interested in exploring binding sites computationally, here are practical first steps:
Essential Software Tools
- PyMOL or ChimeraX: For visualizing protein structures and binding sites
- CASTp or P2Rank: For automatic binding site detection
- AutoDock or Vina: For molecular docking experiments
- VMD: For molecular dynamics simulation analysis
Key Databases
- Protein Data Bank (PDB): Repository of protein structures
- BindingDB: Database of binding affinities
- ChEMBL: Bioactivity data for drug discovery
Learning Path
Start with basic structural biology concepts, then progress through:
- Protein structure fundamentals
- Binding site visualization and analysis
- Molecular docking principles
- Drug design methodologies
Consider enrolling in comprehensive courses like Molecular Modeling and Drug Designing to gain hands-on experience with industry-standard tools and methods.
Future Directions and Emerging Trends
The field continues evolving rapidly with several exciting developments:
Cryo-EM Integration
Advances in cryo-electron microscopy are providing new structural insights into binding sites, particularly for large protein complexes and membrane proteins previously difficult to study.
Personalized Medicine
Binding site analysis is becoming crucial for personalized drug therapy, where treatments are tailored to individual genetic variations that affect protein structure and drug response.
Sustainable Drug Design
Computational binding site analysis reduces the need for extensive laboratory testing, supporting more environmentally sustainable drug discovery processes.
Conclusion
Protein binding sites represent the fundamental interface where molecular recognition occurs in biological systems. Understanding these sites – their structure, types, and computational analysis – is essential for anyone working in molecular modeling, drug design, or structural biology.
From traditional active sites to newly discovered cryptic pockets, each type offers unique opportunities for therapeutic intervention. Modern computational tools make it possible to analyze these sites with unprecedented detail and accuracy, accelerating drug discovery and deepening our understanding of biological processes.
As artificial intelligence and machine learning continue transforming the field, the ability to predict, analyze, and target binding sites will only become more powerful. For students and researchers entering computational biology, mastering these concepts provides a strong foundation for contributing to future breakthroughs in medicine and biotechnology.
Whether you’re interested in designing new antibiotics, developing cancer treatments, or understanding fundamental biological processes, protein binding sites will be at the center of your work – making them essential knowledge for the next generation of computational biologists.
Ready to learn this hands-on, not just read about it? Start free: How to learn molecular docking (step by step).